

在数据中心基础设施的传统支柱(即计算、存储和网络)中,网络具有独特性,因为它本身并无固有价值。虽然独立的服务器仍然可以进行计算,存储设备也可以保存数据,但网络的价值仅取决于其所传输的信息。
同样的逻辑也适用于高性能网络(High-Performance Networking, HPN)。然而,HPN失效的负面影响可能会更为显著。如果数据不能完美、可靠且有序地到达目的地,通常会导致超出基本传输范围的上下游中断。原因何在?因为“高性能”远比单纯的带宽和专用集成电路(Application-Specific Integrated Circuit, ASIC)延迟更为复杂。
网络工程师深知,在传统环境中,分界线在于数据包在一边进入线缆并在另一边交给网络接口卡(Network Interface Card, NIC)的那一刻。这种分界方式简单、明了,便于故障排查(或者至少可以将责任推给其他环节,声称“这不是网络问题”),并且仅涵盖整个流程的极小部分。
本文将探讨高性能网络的组成部分、可用的传输技术以及使其真正实现高速运行的“秘诀”。
高性能网络由哪些部分组成?
- 延迟
数据包通过单个交换机ASIC时,NIC到NIC的延迟通常在100-300纳秒之间(具体数值因芯片和平台而异)。在其他条件相同的情况下,内核到内核的延迟约为50微秒。这意味着什么?大约95%的延迟发生在服务器内部。
要理解这一点,需要深入查看服务器内部的结构,请注意,应用程序、套接字和协议驱动程序都位于主内存中。
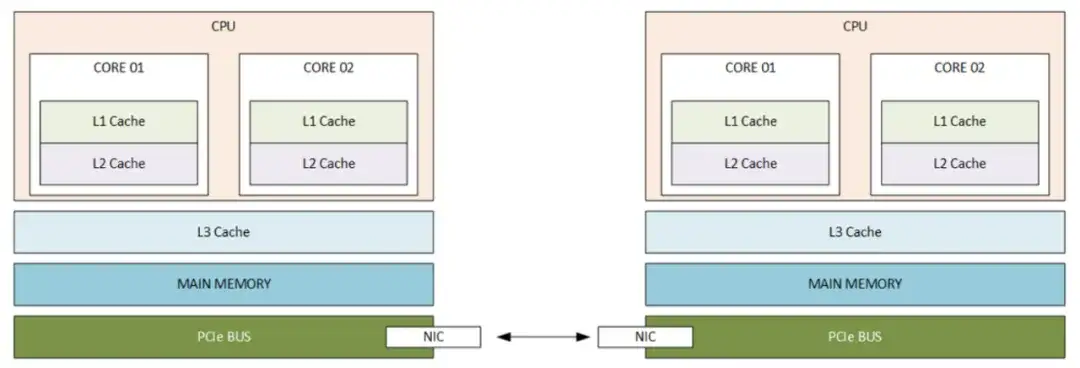
一个高度简化的数据包传输过程(“即数据包的一天”)始于两个8字节寄存器进入CPU,输出一个8字节寄存器,这被视为一个64位浮点运算。从这里开始,我们的数据包需要依次经过L1(极快)、L2(非常快)和L3(较快)缓存、主内存(速度较慢)以及PCI总线,最终到达NIC以传输到另一台设备。
- 带宽
带宽需求不断增长。目前,高性能网络的最低要求是400Gbps,预计在未来两年内将跃升至800Gbps至1600Gbps。带宽是一个不断变化的目标,投资应被理解为具有有限的“顶尖”使用寿命,因为目前被认为是超高速的带宽很快就会变得司空见惯。
尽管如此,尽管实现这种带宽的工程和物理原理相当复杂,且管道的大小确实很重要,但带宽本身并不是使网络“高性能”的因素。
如果不是延迟和带宽,那么是什么让应用程序运行得更快呢?
RDMA:远程直接内存访问,是一种在参与计算设备的NIC上实现的I/O绕过技术。RDMA利用零拷贝网络,即直接从一个设备的主内存读取数据到另一个设备的主内存,同时完全绕过NIC、套接字和在该内存中运行的传输缓冲区。
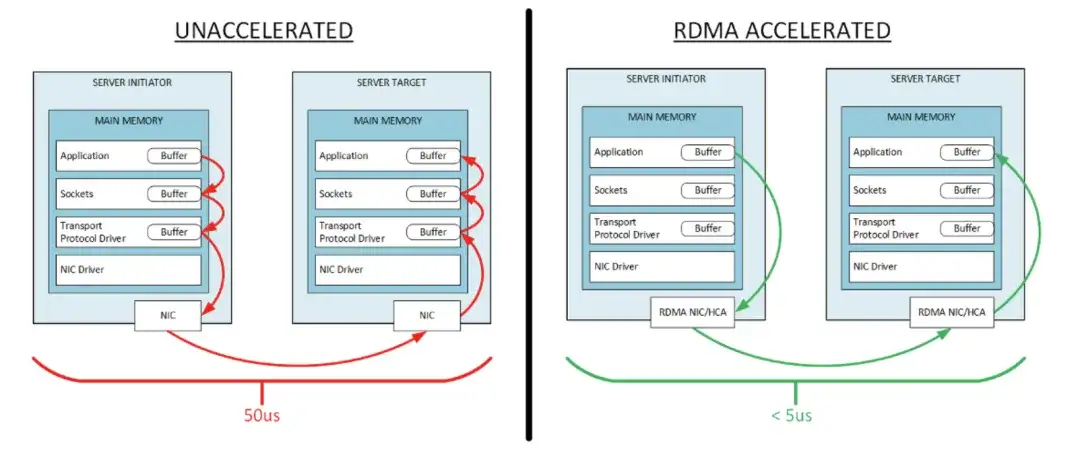
RDMA是一个多学科领域,涉及对应用程序、网络、计算和存储技术的多层面理解。一旦启用RDMA,网络可以实现端到端延迟降低90%至96%(而非NIC到NIC的延迟)。
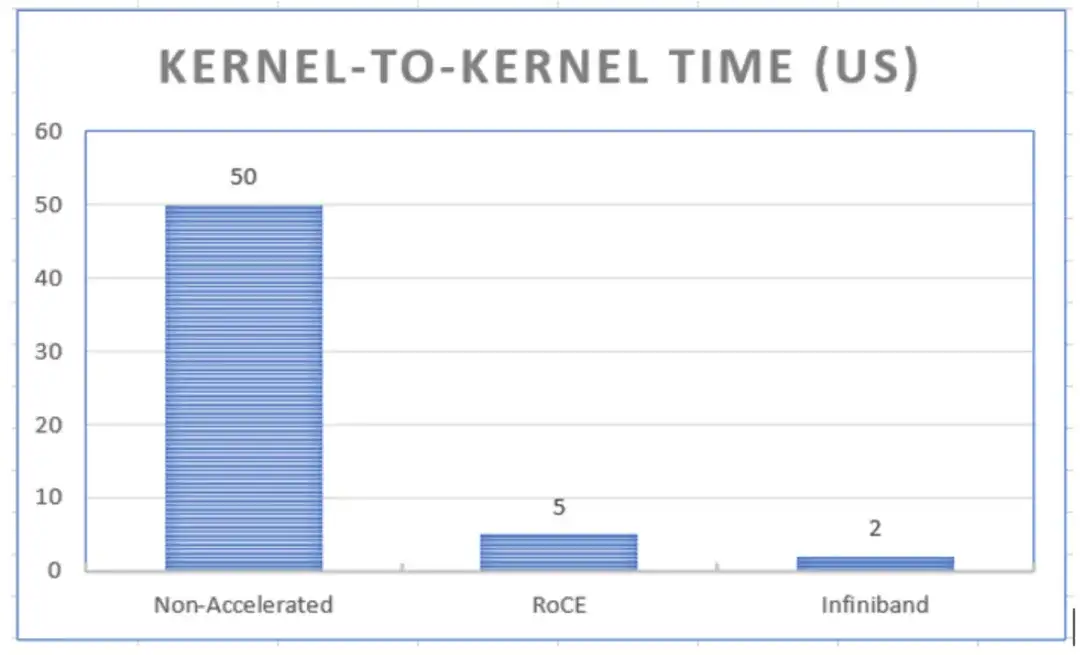
然而,RDMA也有一些缺点。最显著的是,它对质量和可靠性要求极为严格:数据必须可靠、有序地传输,不能出现丢包或抖动,且必须始终如此。标准数据中心网络的“尽力而为”服务等级协议(SLA)是不够的。这就是高性能网络中“高性能”部分的体现。
那么,什么是高性能网络呢?
定义高性能网络的问题并非仅仅是延迟或带宽的问题,尽管这两者都是因素。高性能实际上取决于您如何传输RDMA(或下一个真正重要的应用程序)。就像网络必须适应语音-over-IP、光纤通道-over-以太网以及数十种其他“敏感应用程序”一样,现代网络也必须适应当今高端计算和存储功能的需求。
目前,有两种主要的行业标准方法用于RDMA传输:
InfiniBand
InfiniBand是一种支持RDMA的通信标准。InfiniBand ASIC的延迟和带宽大致相当于以太网性能。实际上,IP-over-InfiniBand的延迟与未加速的IP-over-以太网相同。其物理硬件包括主机通道适配器(Host Channel Adapter, HCA,本质上是一种NIC)和InfiniBand交换机。它是一种基于控制器的架构(通过子网管理器),是非可路由的,这意味着故障域的大小与整个网络结构相同。子网管理器在其中一个交换机上以软件形式运行。
RoCEv2
RoCE(读作“rocky”)是一种类似的利用以太网的标准,但经过了一些调整。它也由HCA和交换机组成,但依赖于HCA点对点协商来实现可靠传输,而不是基于InfiniBand的控制器。必须在交换机上配置优先流量控制(Priority Flow Control, PFC)和显式拥塞通知(Explicit Congestion Notification, ECN)参数,以识别和优先处理与RDMA相关的流量。
选择哪一种取决于工程偏好和根深蒂固的信仰。
InfiniBand与RoCE的考量
以下是一个快速对比:

灵活性
InfiniBand网络是为特定工作负载(如人工智能)量身定制的,只能支持一种类型的工作负载。如果客户的数据中心仅包含有限数量的持续运行且性能特征相似的人工智能工作负载,那么InfiniBand可能是一个不错的选择。高性能以太网则更具灵活性。如果客户的数据中心专注于云计算(混合云或云就绪)或包含多种不同需求的应用程序生态系统,那么以太网/RoCE可能是更好的选择。从InfiniBand迁移到以太网可能会面临挑战。
可扩展性
随着人工智能/机器学习工作负载的增长,数据中心的规模也将扩大。如果当前的增长趋势持续下去,今天的NVIDIA SuperPOD DGX集群(127个节点/1016个GPU)将在两年内需要扩大20倍。虽然InfiniBand的规范允许构建非常大的网络结构,但在面对大型故障域时可能会出现一些复杂情况。InfiniBand没有Layer 3选项。
何时使用每种技术?
最佳实践建议将InfiniBand用于最具挑战性和对性能要求最高的应用程序(即不仅仅是任何人工智能模型,而是真正大型的人工智能模型)。其他95%的用例可以在更具灵活性的以太网选项上舒适运行。
2022年,Meta进行了一项研究,比较了其LLAMA2人工智能模型的预训练时间。研究中构建了两个相同的集群:一个基于InfiniBand,另一个基于RoCEv2。研究发现,在2000个GPU以下时,两者的性能非常接近。以当前的机架密度和定价来看,2000个GPU需要大约63个机柜,成本约为1亿美元,并且需要超过一年的时间来构建。
行业普遍共识是,尽管InfiniBand始终有其用武之地,但基于以太网的解决方案将不断发展,以满足大部分市场需求。
参考文档: